Building a Local LLM Playground with Ollama on Proxmox - Part 2

In my previous article, I described how to stand up a self-hosted LLM playground on commodity server hardware with a single mid-range GPU. That setup supported three primary use cases:
- General-purpose development
- LLM-focused evaluation
- GPU-intensive tasks like gaming
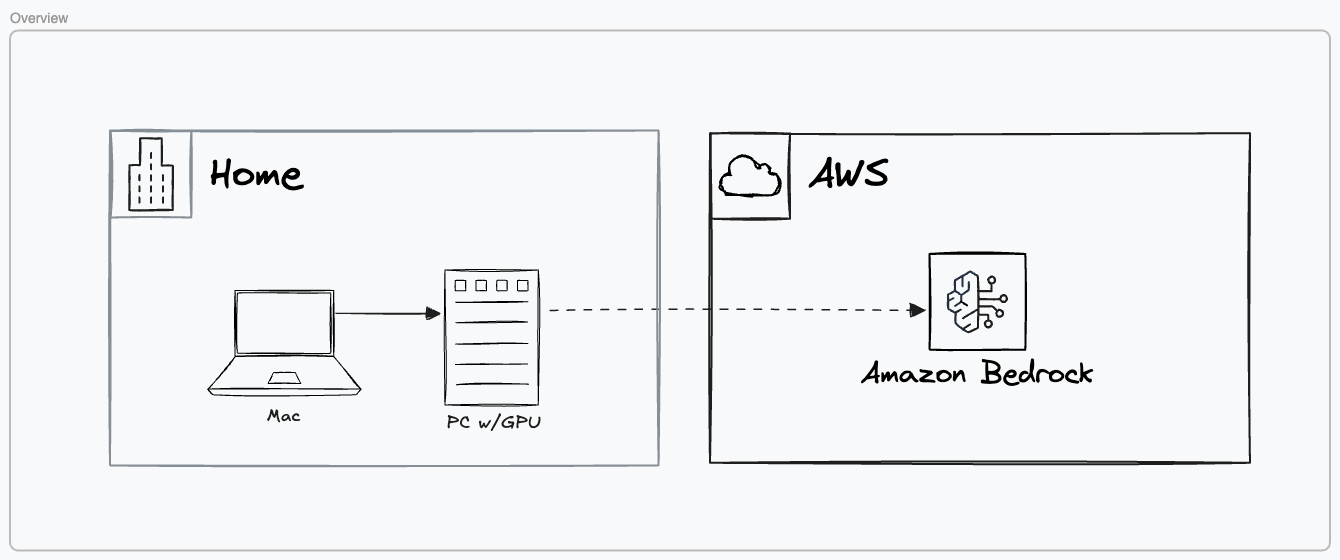
The core of this environment is a Linux server running on bare metal and a MacBook as the roaming client. The server is wired into my local network and backed by a UPS, while the MacBook serves as the primary interface. For cloud augmentation, optional connections to Amazon Bedrock or similar providers are available, though we’ll stay focused on the self-hosted side for now.
Expanding the Architecture
This article explores the supporting services around the GPU, which add flexibility, performance, and robustness to the overall environment. Namely, we'll be adding Open WebUI for direct interaction with models, and Bedrock Access Gateway with an AWS account for dozens of models on tap to add to our playground.
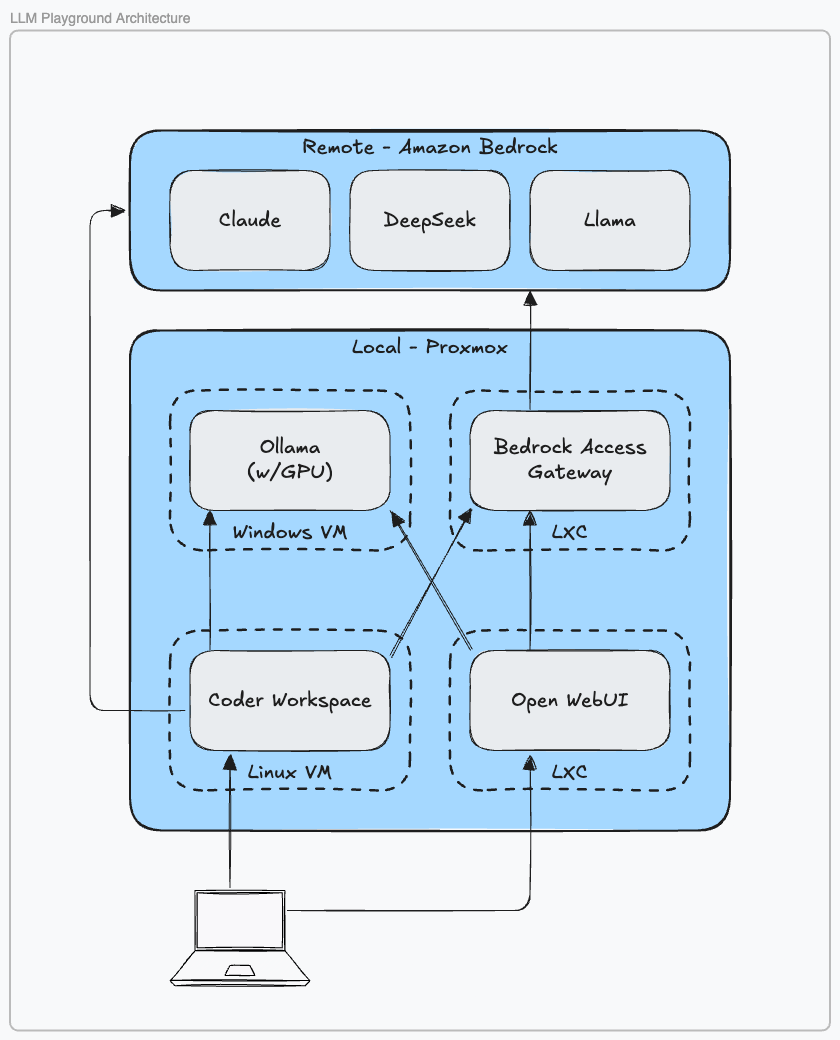
The home server runs Proxmox directly on the hardware, hosting the following virtual machines and containers:
Windows VM: Ollama
Runs as a service that provides OpenAI-compatible endpoints and a CLI to download and serve a range of open-source LLMs, including Meta’s Llama, Google’s Gemma 3, and other community-maintained models.
Linux VM: Coder
Delivers Docker-based development environments with envbuilder, integrates with IDEs like Cursor, Windsurf, and VS Code, and supports ad-hoc port forwarding for local testing.
Linux LXC: Open WebUI
Provides a front-end for LLM interaction, supporting Ollama or OpenAI endpoints, local RAG with web search, and role-based access control (including LDAP for local authentication).
Linux LXC: Bedrock Access Gateway
A lightweight proxy provided by AWS. It can run on your network or in your VPC as a Lambda, and it exposes OpenAI-compatible endpoints to interact with Amazon Bedrock models.
A Day in the Workflow
A typical session looks like this:
- Open the MacBook and connect to the Coder instance.
- Select a workspace, which Coder spins up with
docker run - Launch Windsurf to begin coding in a remote IDE
Most of my work happens in Windsurf, connected remotely to my Coder workspace, but Open WebUI remains handy for experimentation. Still, one question lingers: what if you need a 32GB GPU without the budget for one?
Extending with Bedrock
That is where the Bedrock Access Gateway comes in. With an AWS account and a single IAM role, it is possible to extend local models with the speed and variety of Amazon Bedrock's catalog of models.
Local inference with Llama 3.2 can take several seconds per response. In comparison, AWS Nova Lite often starts responding in under a second, with dozens of other models available on demand.
Alternatives like LiteLLM or OpenRouter offer similar functionality, but I prioritize keeping traffic inside a trusted perimeter. Whether that is the home lab network or a dedicated AWS VPC, this design keeps control close to the operator.
Streamlined Connectivity
Because Coder runs as a VM alongside its peers, it acts as the single ingress point to the environment. That reduces firewall complexity to a single open port and makes it straightforward to add VPN functionality.
For remote access, I use pfSense with the Tailscale package, which turns the server into a WireGuard VPN exit node. With subnet routing enabled, I can connect from anywhere and work as if I were sitting in front of the machine.
Lessons from Iteration
This setup is the product of several iterations. Along the way, I asked myself some hard questions.
Why Not Docker Compose?
I initially ran Kubernetes with Kubespray, ArgoCD, and Helm. It worked, but when Kubernetes failed, it failed hard, often leaving my cluster broken for months at a time. There’s nothing like a broken k8s cluster to sharpen your SRE skills!
The fallback was Docker Compose on my MacBook, but that quickly hit limitations:
- Architecture mismatches between
amd64images and Apple’sarm64hardware - Networking headaches with DNS, port forwarding, and host/guest communication
- Limited scalability with no simple way to add CPU resources without jumping back to Kubernetes
Proxmox ended up striking the balance: easier to manage than Kubernetes, but more scalable and reliable than Docker on macOS.
Why Not Just Use ChatGPT?
Cost is one factor. Hardware investments help insulate against rising subscription fees. But the bigger issues are security, governance, and flexibility.
Handing sensitive data to a third party comes with risk. OpenAI is great for OpenAI models, but what if you want to evaluate multiple vendors, swap models with minimal friction, or control your data end to end? Owning the architecture provides that freedom, and the learning experience is invaluable.
What’s Next
This article highlighted a slice of my home lab, centered on Proxmox and Coder, and walked through the workflow that anchors my daily development. In upcoming pieces, we will explore:
- Self-hosted evaluation with LangFuse, PostHog, and Ragas
- Backup strategies with Restic across VMs and containers
- Queryable backup management with an MCP server
Until then, keep building – and keep learning!